https://arxiv.org/pdf/1905.09274.pdf
The WhitePaper Reading Club
February 7, 2024 [Session 11]
Blurb
Lazy Ledger, proposed by Mustafa Al-Bassam, suggests blockchains do not scale because they undertake too many tasks. Most blockchains require nodes to agree on the order of messages, store them, and verify the validity of these messages. Consequently, scaling transaction throughput becomes challenging. To address this, Mustafa segmented a blockchain into the following layers:
- Consensus: Determines the transaction order on the chain.
- Data Availability: Ensures access to data on the chain.
- Client: Verifies the data's validity (on/off-chain).
Lazy Ledger concentrates on the data availability layer, employing a "Namespaced Merkle Tree" and "two-dimensional erasure coding" (for Fraud Proofs) )to guarantee efficient and dependable data storage and retrieval. There are other approaches to this such as Avail, Eigen DA among others.
Key Terms
- Transaction Validity: Criteria determining whether a transaction is correct ( and acceptable). Lazy Ledger believes this can be customized by the developers of the blockchain or application and not the chain developers.
- Block Validity Rule: Conditions a block must meet to be considered valid.
- Probabilistic Validity Rules: An efficient way to validate data (e.g., transactions or blocks) with a high degree of certainty.
- Consensus Rules: How a blockchain agrees on what to include in a block.
- Data Availability: Ensures that all the data needed to reconstruct the state of the blockchain (e.g., transactions in a block) is available and accessible to participants.
- Application Model: How applications are built and interact with the blockchain, including how they process transactions and manage state.
- Erasure Encoding: A way of encoding data (adding extra data to the ordinal data) such that original data can be reconstructed even if some pieces are missing or withheld.
- Random Sampling: An efficient way to check the availability and integrity of data by randomly asking for small parts of the data set.
- Sharding: Splitting data into smaller (shards) to improve and reduce the need to filter for data from all the data. A common technique used in scaling databases.
- Header (Block Header): A summary of a block's information, including the previous block's hash, timestamp, and Merkle root of transactions.
- Block Producer: Entities or nodes responsible for creating new blocks in the blockchain by gathering transactions, executing them (if applicable), and applying consensus rules.
- Client: Users or applications interacting with the blockchain, submitting transactions, querying state, or participating in consensus through full or light node implementations.
Questions
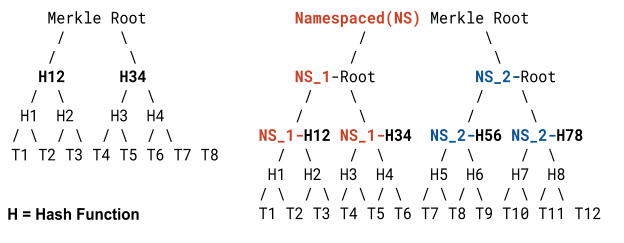
- Namespaced (“NI”) Merkle trees (section 5.2):
- How does it work? A possible explanation is that NI Merkle tree “split” a Merkle tree by “Namespaces”. The trees is structured so that leaves belonging to the same namespace are grouped together. This is similar to sharding.
- What is a concrete example of a NI function? Could this be a way to add NI to a message: [NI]-Hash([MESSAGE]) → 0x02-Hash(“hi”)
- Is there a single “Namespaced Merkle” tree or multiple?
- Does the NI need to be globally unique?
- Is the above assumption of names spaced Merkle Tree correct?
-
Blockchains (section 2.1): Is there a consensus on how to define blockchains? Projects can simply redefine a blockchain to suit their beliefs.
-
Two-Dimensional Erasure Encoding (section 2.2): How does data recovery work in a 2-dimensional “erasure encoded” data block? Why is it based on a single column or row?

-
Virtual Chains (section 1): How do they define virtual chains? Is this a correct analogy?
-
Incentive: What incentivizes someone to store your data? Data retrievability is something that FileCoin and other file storage networks have solved. However, the paper doesn’t describe any incentives.
-
Impact on Smart Contracts: How might LazyLedger's client-side approach to smart contracts change the way developers create and users interact with decentralized applications?
Observations
- Similar to FileCoin, MasterCoin, and even Inscriptions on Bitcoin. Essentially, this is a decentralized file storage platform, explicitly focused on storing blockchain data.
- MasterCoin became OmniLayer.
Competitors
- Avail: https://docs.availproject.org/about/introduction
- EigenDA: https://docs.eigenlayer.xyz/eigenda/overview
- Arbitrum Nitro: https://github.com/OffchainLabs/nitro/blob/master/docs/Nitro-whitepaper.pdf
- Kyve https://www.kyve.network
Further Readings
- Reed Solomon Erasure Encoding: https://chat.openai.com/share/5a0e7ff3-f324-47e4-8e50-5372bd20d6f5
- KZG Erasure Encoding: https://blog.subspace.network/combining-kzg-and-erasure-coding-fc903dc78f1a
- Lazy Ledger Demo Code: https://github.com/celestiaorg/lazyledger-prototype
- MasterCoin: https://chat.openai.com/share/4627882c-79d1-4ea9-bdf8-0a8d7f586740
Technical Co-Founders
Mustafa Al Bassam
- Co-founded the hacking group LulzSec, known for high-profile cyberattacks in 2011.
- Ph.D. in Information Security at University College London
- Co-founded Celestia Labs, serving as CEO
- Co-founded Chainspace, a blockchain project acquired by Facebook in 2019.
Ismail Khoffi
- Early Tendermint engineer developer,
- Scientific / Staff Engineer SCAI
- Interchain Foundation engineer
- Security/research engineer at Google
Other Learning Resources:
- Video Sponsored by Celestia: https://www.youtube.com/watch?v=ToHbt8pYBfA (note, much of this information is just summaries)
Meeting Notes + Discussions
- Settlement: finality
- Consensus: Agreement
- Ethereum data blobs is the same as data aviablity - blobs store multiple - EIP 4844.
- Decentralization - does it sacrifice this alot