Stable Draft
| The WhitePaper Reading Club KL [01] | 14 Feb 2025 |
|---|---|
| LayerZero: QMDB: | Yudhishthra, Shuenrui |
| https://arxiv.org/pdf/2501.05262 |
LayerZero is an omnichain messaging protocol that enables secure, efficient, and customizable cross-chain communication. At its core, LayerZero utilizes Ultra Light Node (ULN), a lightweight verification system that minimizes on-chain storage by leveraging Decentralized Verifier Networks (DVNs) instead of full blockchain nodes. In LayerZero V2, ULN allows application owners to configure their own verification models using an "X of Y of N" authentication system, where multiple independent verifiers must confirm a transaction before execution. Once the Security Stack verifies the message payload, Executors automate execution on the destination chain, handling gas management, and providing customizable gas settings to optimize transaction costs.
Summary
Quick Merkle Database (QMDB) is a state-of-the-art verifiable key-value store that significantly improves scalability, efficiency, and verification by integrating key-value storage and Merkle tree data structures into a unified framework.
Why This Is Important
QMDB enhances blockchain performance by reducing storage bottlenecks, minimizing SSD read/write overhead, and supporting high-throughput applications, making it a crucial innovation for blockchain scalability and decentralization.
Key Innovation
QMDB introduces an append-only, twig-based structure that allows state updates with O(1) IO operations, reducing write amplification and enabling efficient in-memory Merkleization. It achieves up to 6× throughput over traditional solutions like RocksDB and 8× over NOMT, scaling to billions of state entries with minimal memory usage.
Overview
QMDB is designed to address the inefficiencies of blockchain state management by unifying key-value storage and Merkle tree verification. Traditional blockchain storage solutions suffer from high write amplification, expensive random writes, and excessive DRAM requirements. QMDB resolves these issues by storing state updates in an append-only structure, eliminating unnecessary SSD accesses for Merkleization, and optimizing the use of DRAM. The system can handle up to 2.28 million state updates per second, enabling 1 million token transfers per second, while scaling efficiently from consumer-grade hardware to enterprise-level infrastructure.
Background
(i) Traditional Databases read/write performance is primarily constrained by disk I/O latency, random writes, and amplifications. Reads are faster when data is cached in DRAM, but writes are bottlenecked by random SSD writes and log-structured merges (LSM trees) in traditional key-value stores like RocksDB. Blockchain state management typically relies on Merkle Patricia Tries (MPT), which suffer from inefficiencies due to random SSD writes and high memory overhead.
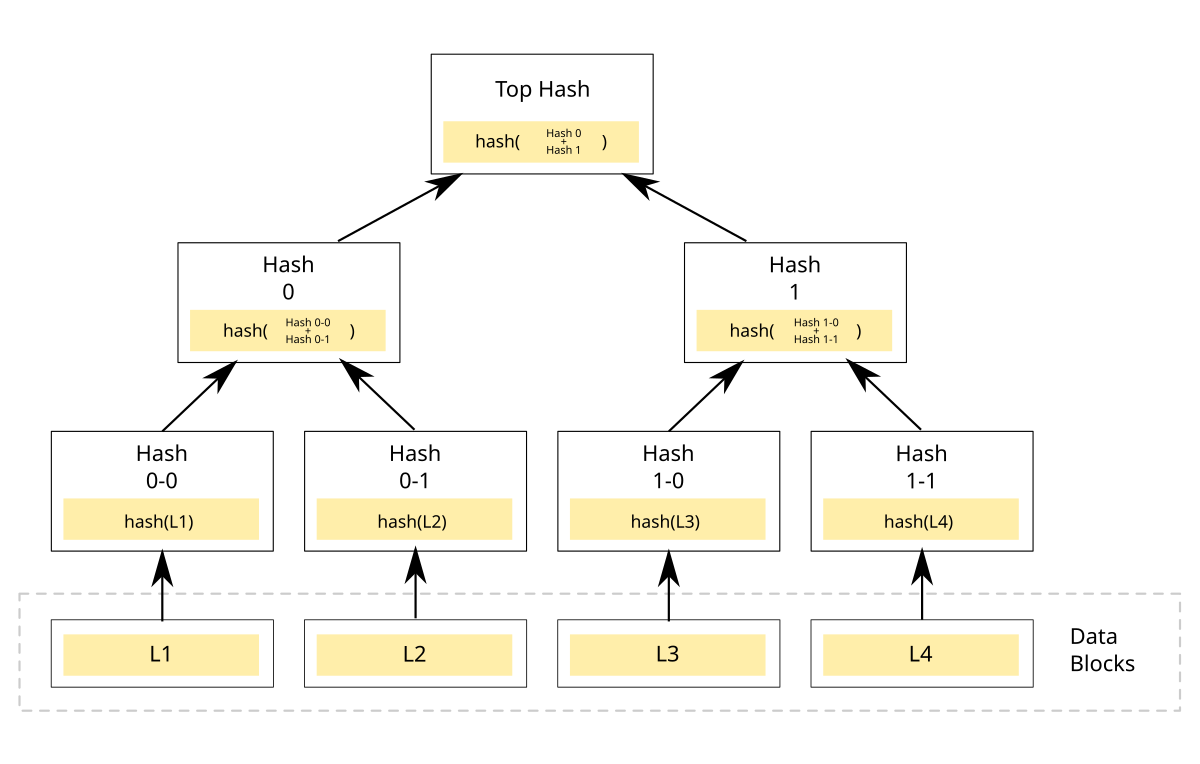
NOTE: Merkle Tree NOT Merkle Patricia Trie
(ii) QMDB integrates a novel authenticated data structure that merges Merkleization with a highly optimized storage backend. Instead of doing Merkleization separately, QMDB stores both world state (blocks of transactions from all blockchains) and Merkle tree data (proof of transaction inclusion in tree) in a single format, reducing redundant data storage and I/O operations. It eliminates the need for separate key-value stores like RocksDB, leading to 6× the throughput over RocksDB and 8× over NOMT (a leading verifiable database).
(iii) By leveraging twigs—compact subtrees with fixed-sized entries—QMDB minimizes the computational burden of state updates while ensuring provable security.
(iv) The system includes historical proof capabilities, allowing efficient access to past blockchain states, a critical feature for auditing and compliance.
Team
QMDB is developed by LayerZero Labs, a pioneering team in blockchain interoperability and storage optimization. The key contributors include:
(1) Ryan Zarick – Co-founder and CTO of LayerZero Labs, leading the architectural design and optimization of QMDB.
(2) Isaac Zhang – Lead Researcher, specializing in high-performance storage systems and authenticated data structures.
(3) Bryan Pellegrino – Co-founder and CEO of LayerZero Labs, overseeing strategic development and real-world blockchain integration.
Opinions
QMDB represents a paradigm shift in blockchain storage, offering a scalable, efficient, and verifiable alternative to existing state management systems. Its ability to handle high transaction throughput while reducing computational and storage overhead makes it a promising solution for next-generation blockchain networks.
Components
(Key Innovations - focus on the innovations, and key parts)
| Twig-based append-only storage | QMDB organizes state data into twigs—fixed-size immutable subtrees—allowing Merkleization without SSD read/write operations. This structure dramatically reduces storage overhead and enhances efficiency. |
|---|---|
| In-memory Merkleization | Unlike conventional storage models that require costly I/O operations for proof generation, QMDB performs Merkleization entirely in-memory, making proof generation orders of magnitude faster. |
| Optimized indexing | The system utilizes a hybrid indexer that balances DRAM efficiency with fast lookups, ensuring seamless state transitions and historical proof retrieval. |
| Parallelized state updates | Through sharding and pipelining, QMDB achieves high parallelization, enabling it to handle millions of updates per second while minimizing contention and latency. |
| Scalability and adaptability | Capable of supporting over 280 billion state entries, QMDB can function on both enterprise-grade servers and consumer hardware, democratizing blockchain participation. |
| Historical proofs and state retrieval | QMDB introduces efficient mechanisms for querying historical blockchain states, enabling use cases such as decentralized auditing, forensic analysis, and retroactive state verification. |
Questions
- How does QMDB ensure security while maintaining high transaction throughput?
- What are the trade-offs of using an append-only storage model compared to traditional blockchain storage solutions?
- How does QMDB handle blockchain reorganization and state pruning efficiently?
- What implications does QMDB have for future decentralized applications beyond token transfers?
References
(1) https://arxiv.org/pdf/2501.05262
(2) https://github.com/LayerZero-Labs/qmdb
Discussion Dump
How does Layer zero work?
LayerZero is an omnichain messaging protocol—a system intentionally designed to help different blockchains communicate securely and efficiently. Instead of each blockchain needing to know all the details about every other blockchain, LayerZero creates a way for them to share only the essential information required to process cross-chain transactions. Here’s how it works:
LayerZero uses a lightweight verification system called an Ultra Light Node (ULN). Unlike a traditional full node that stores and verifies every detail of a blockchain, a ULN only stores minimal data such as block headers. When a transaction is sent from one blockchain to another, the ULN relies on a network of decentralized verifiers (DVNs) to check the transaction's validity. This network verification is often set up using an "X of Y of N" model, meaning a transaction must receive approval from a predefined number of independent verifiers before it is executed.
Once these verifiers confirm the validity of the message payload, a set of components known as Executors take over. Executors manage the actual execution of the transaction on the destination blockchain and handle gas management, which helps optimize transaction costs.
What is a block header?
A block header typically refers to the summary section of a block in blockchain technology. It contains key metadata about the block that is used in various ways including verifying the block's integrity, linking it to previous blocks, and facilitating consensus mechanisms such as proof of work.
In many blockchain implementations like Bitcoin, for example, a block header includes information such as:
- The version of the blockchain protocol utilized.
- The hash of the previous block, which connects this block to the chain.
- The Merkle root, a single hash that summarizes all the transactions contained within the block.
- The timestamp indicating when the block was created.
- The difficulty target, which helps adjust the complexity of mining new blocks.
- The nonce, a number that miners adjust to try to produce a hash that meets the network's difficulty requirements.
By assembling all these elements into the block header, the blockchain ensures that each block is securely linked to its predecessor, maintaining the integrity and chronological order of the ledger. This design is fundamental to preventing tampering and ensuring that the network reaches consensus on its transaction history.
Example: Transferring Tokens from Blockchain A to Blockchain B
- Initiating the Transfer on Blockchain A:
- Action: Alice wants to move tokens from Blockchain A (e.g., Ethereum) to Blockchain B (e.g., Binance Smart Chain).
- Blockchain State Update: She sends a transaction to a smart contract on Blockchain A that locks (or burns) her tokens. This action updates the blockchain state data on Blockchain A, reflecting that her tokens are now secured in the contract.
- Role of QMDB/State Data: In systems like LayerZero using specialized storage (such as QMDB), the change in state (the locked tokens) is recorded efficiently and a cryptographic proof (e.g., a Merkle proof) of this updated state is generated quickly. This proof serves as evidence that the state change is legitimate.
- Sending the Cross-Chain Message:
- Action: The LayerZero protocol takes the event (the token lock) along with the cryptographic proof generated from the updated blockchain state.
- Role of State Data: The state data—and the associated proof—is critical because it verifies that the tokens were indeed locked on Blockchain A, ensuring trustlessness when the message is transmitted to another chain.
- Receiving the Transfer on Blockchain B:
- Action: The cross-chain message, complete with the Merkle proof, is received by a gateway or smart contract on Blockchain B.
- Verification Process: The receiving contract uses the proof to verify that Blockchain A’s state indeed shows the tokens as locked. Only when this verification is successful does the contract proceed.
- Blockchain State Update on B: Once verified, Blockchain B updates its own state data—either by releasing previously locked tokens or by minting new tokens for Alice. This update reflects that Alice now has access to tokens on Blockchain B.
Where Does Blockchain State Data Come In?
-
Record of Transactions: The blockchain state on each network captures the current status (for example, account balances and token locks). This data acts as the "source of truth" for what is happening in the system.
-
Basis for Verification: The cryptographic proofs (like those generated by QMDB) are derived directly from the blockchain state data. They allow the receiving chain to independently confirm that the state change on the originating chain (token locking) genuinely occurred.
-
Ensuring Trustless Communication: Since LayerZero relies on the integrity of each chain’s state data, any cross-chain message is backed by verifiable changes. This ensures that a token transfer isn’t executed unless the originating state update is confirmed.
Pre‑QMDB Solutions Overview (not important just read 2)
Below are several approaches used before QMDB was introduced, presented with a clear structure detailing how each solution worked and the limitations it faced.
MPT Paired with Key‑Value Stores (e.g., RocksDB)
How It Worked: • The blockchain’s world state (account balances, contract storage, etc.) was maintained using Merkle Patricia Tries (MPTs). • The MPT was persisted in a general‑purpose key‑value database such as RocksDB, enabling cryptographic proof generation for state data.
Limitations: • Each state update required multiple disk I/O operations, resulting in high write amplification. • Significant performance bottlenecks emerged due to the need to read and re‑write parts of the state from/to disk. • A large in‑memory footprint was necessary to mitigate these I/O challenges, increasing resource overhead.
Incremental Optimizations: NOMT (Nearly‑Optimal Merkle Trie Database)
How It Worked: • NOMT optimized the standard MPT‑RocksDB approach by employing a flash‑optimized layout that streamlined state updates. • It reduced write amplification and attempted to better integrate state storage with cryptographic proof generation.
Limitations: • The architectural separation between the physical key‑value storage layer and the Merkle proof generation layer still imposed inefficiencies. • Duplicated data interactions led to extra disk I/O and memory overhead that could not be fully eliminated.
AVL Tree‑Based ADS
How It Worked: • This alternative used self‑balancing AVL trees instead of tries to maintain the blockchain state, offering faster lookups and updates due to inherent tree balancing.
Limitations: • Each state update still led to O(log N) node modifications, which constrained scalability. • The structure was path‑dependent, meaning the state root depended on the specific order of updates, complicating verification processes.
LVMT (Layered Verification Model Trees)
How It Worked: • LVMT introduced a layered storage model using vector commitments to support constant‑time Merkle root updates. • It combined an append‑only Merkle tree with an additional Addressable Merkle Tree (AMT) to handle inclusion, exclusion, and latest‑value proofs.
Limitations: • Maintaining the extra AMT and performing vector commitment computations increased resource overhead. • LVMT focused on ADS design rather than providing a fully unified, verifiable end‑to‑end storage solution.
MoltDB
How It Worked: • MoltDB improved upon the two‑layer MPT design by segregating state data based on recency. • It paired this segregation with a compaction process to reduce I/O operations and enhance throughput compared to systems like Geth.
Limitations: • The throughput improvements were incremental (around a 30% boost) and did not eliminate the inherent inefficiencies of the traditional two‑layer architecture. • It still suffered from the duplicated data operations and the related performance overhead.
Merkle Mountain Ranges (MMRs)
How It Worked: • MMRs are an append‑only structure consisting of multiple Merkle subtrees (peaks). • As new records are appended, equally sized peaks are merged, leading to compact inclusion proofs for sequential data.
Limitations: • MMRs are not designed for live state management because they do not support deletions, updates, or keyed lookups naturally. • They lack native support for generating exclusion proofs, limiting their use to historical data verification rather than dynamic state management.
MoeingADS
How It Worked: • MoeingADS utilizes an append‑only Merkle tree with a memory‑efficient representation that supports both exclusion and latest‑value proofs. • It processes compaction and exclusion maintenance in batches after several blocks, aiming to reduce per‑update overhead.
Limitations: • Batch processing of updates can adversely impact real‑time performance and overall throughput. • The design is less suitable for environments that require immediate, streaming transaction handling or stateless validation.
Verifiable Ledger Databases
How It Worked: • Systems such as GlassDB, Amazon’s QLDB, Azure’s SQLLedger, and Alibaba’s LedgerDB use Merkle tree variants to maintain an append‑only log, ensuring data integrity via deferred verification. • These solutions focus on providing transparency and verifiability for historical logs.
Limitations: • They are optimized for retrospective verification rather than frequent, live state updates. • The focus on historical data and deferred verification makes them less efficient for dynamic blockchain state management, where real‑time state access is critical.
In Summary
Before QMDB, blockchain systems typically relied on a two‑layer approach that combined a key‑value store (like RocksDB) with an MPT or its alternatives for Merkleization. Despite various incremental optimizations—including NOMT, AVL tree‑based ADS, LVMT, MoltDB, MMRs, MoeingADS, and verifiable ledger databases—each solution faced challenges such as high disk I/O operations, write amplification, excessive memory overhead, or limitations in handling live state updates. QMDB was introduced to unify state storage and proof generation into a single, optimized verifiable key‑value store, substantially reducing extra I/O and memory requirements while delivering higher throughput and better scalability.
Light Node vs Full node
Ultra light node (ULN) is essentially a specialized form of a light node designed for cross-chain messaging, particularly tailored in protocols like LayerZero. While the core idea is similar to that of traditional light nodes, ULN incorporates additional mechanisms to streamline verification for cross-chain communications.
Below is a comparison between Light Node / Ultra Light Node and Full Node:
| Feature | Light Node / Ultra Light Node (ULN) | Full Node |
|---|---|---|
| Data Storage | Stores minimal data, such as block headers and cryptographic proofs | Stores the complete blockchain data, including every transaction and block detail |
| Computation & Resources | Requires less storage and computational power, making it suitable for resource-limited environments | Demands high resources in terms of storage, processing power, and bandwidth |
| Verification Process | Uses simplified verification methods via cryptographic proofs and may rely on external verifiers (e.g., DVNs) | Performs full verification of each transaction and block independently |
| Security | Provides adequate security by validating essential data and leveraging decentralized verifiers; however, it relies on summary data rather than full details | Offers a high security level by verifying and storing the entire blockchain history |
| Synchronization Speed | Synchronizes quickly due to handling only a small subset of data | Synchronizes more slowly because it needs to download and verify all blockchain data |
| Use Cases | Ideal for applications like cross-chain messaging, mobile clients, and decentralized bridges (e.g., LayerZero's ULN) | Often used in core network infrastructure to ensure full transactional accuracy and integrity |
In short, Layer Zero utilizes Ultra Light Node (ULN), by leveraging Decentralised Verifiable Network (DVN).
What is a Decentralised Verifiable Network (DVN)?
In the context of LayerZero’s cross-chain messaging protocol, a DVN is a group of independent entities that work together to check that a message sent from one blockchain is valid before it’s executed on another blockchain.
The Security Verification Model “X of Y of N” is introduced for this case.
What does “X of Y of N” mean?
Imagine you have a panel of referees who need to decide whether the player is foul, instead of asking all the referees every time—which could be slow —you select a smaller group of them to give their opinions. This is essentially what the "X of Y of N" model does.
In this model, "N" represents the total number of available verifiers. For each transaction, you choose "Y" verifiers out of these available N people. Then, the system requires that at least "X" out of the chosen Y verifiers agree that the transaction is valid before the message goes through.
For example, suppose there are 10 verifiers in total (N = 10). For a particular transaction, you might randomly pick 5 of them (Y = 5) to review it. Then you set a rule that at least 3 of these 5 (X = 3) must confirm the transaction. If 3 or more say it’s okay, the transaction is executed.
Benefit of “X of Y of N”:
- It speeds up the verification process because not every verifier is asked to weigh in every time.
- It maintains security by still requiring multiple independent checks.
- It lets application owners adjust the numbers (X, Y, and N) to balance speed, cost, and security depending on their needs.
In simple terms, the "X of Y of N" model is like having a small committee from a larger pool of experts, where you only need a majority of the committee to agree on a decision for it to become final.
How does QMDB minimize SSD read/write overhead and achieve high-throughput?
Quick Merkle Database (QMDB) minimizes SSD read/write overhead and supports high-throughput applications by smartly combining key-value storage with Merkle tree data structures. Here’s a simple breakdown:
-
Efficient Updates: In a typical database, every change might cause many disk operations. With QMDB’s integrated Merkle tree, only the affected parts of the tree (the branch leading to the changed key) need updating. This focused update process means that fewer and smaller changes are written to the SSD, reducing the overall read/write operations.
-
Optimized Verification: The Merkle tree structure enables fast and efficient verification of data integrity. Instead of reading the entire dataset from the SSD to check if data is correct, QMDB only verifies a small set of hashes from the tree. This speeds up transaction processing and minimizes the need for heavy disk reads.
-
High Throughput: By reducing expensive disk operations and streamlining data verification, QMDB can process many operations concurrently. This means more transactions per second can be handled, which is crucial for blockchain systems that require rapid processing without bottlenecks.
What is Twig?
Below is an explanation in simple terms:
A twig-based structure is a special way QMDB organizes and updates its data. Imagine a tree where instead of managing every single branch and leaf in one massive structure, you have little offshoots or "twigs" where each new piece of data simply gets appended to the end. Because of this design, when you update the database, you only need to modify a small section—a single twig—instead of rewriting large portions of the entire tree.
This design is important because it leads to several improvements:
-
Constant-Time Updates: Every state update can be done with O(1) input/output (IO) operations. In practical terms, this means each change takes roughly the same amount of time regardless of how big the overall database is. By focusing on just one twig, the system avoids extensive read and write operations.
-
Reduced Write Amplification: Traditional databases might rewrite many data blocks for every update, which can strain SSDs. With an append-only, twig-based structure, only the affected twig is written to disk. This minimizes excessive disk writes, preserving the SSD’s lifespan and making each update cheaper and faster.
-
Efficient Merkleization: Because the twigs can easily integrate into an in-memory Merkle tree, only the small parts that changed need to be rehashed for integrity verification. This makes checking that data hasn’t been tampered with much more efficient, which is crucial for security in blockchain applications.
-
High Throughput & Scalability: The combination of constant-time updates and minimal disk operations not only speeds up transactions but also allows the database to support billions of state entries using minimal memory resources. This efficiency translates into a throughput that can be up to 6× higher than traditional solutions like RocksDB and 8× higher than NOMT.
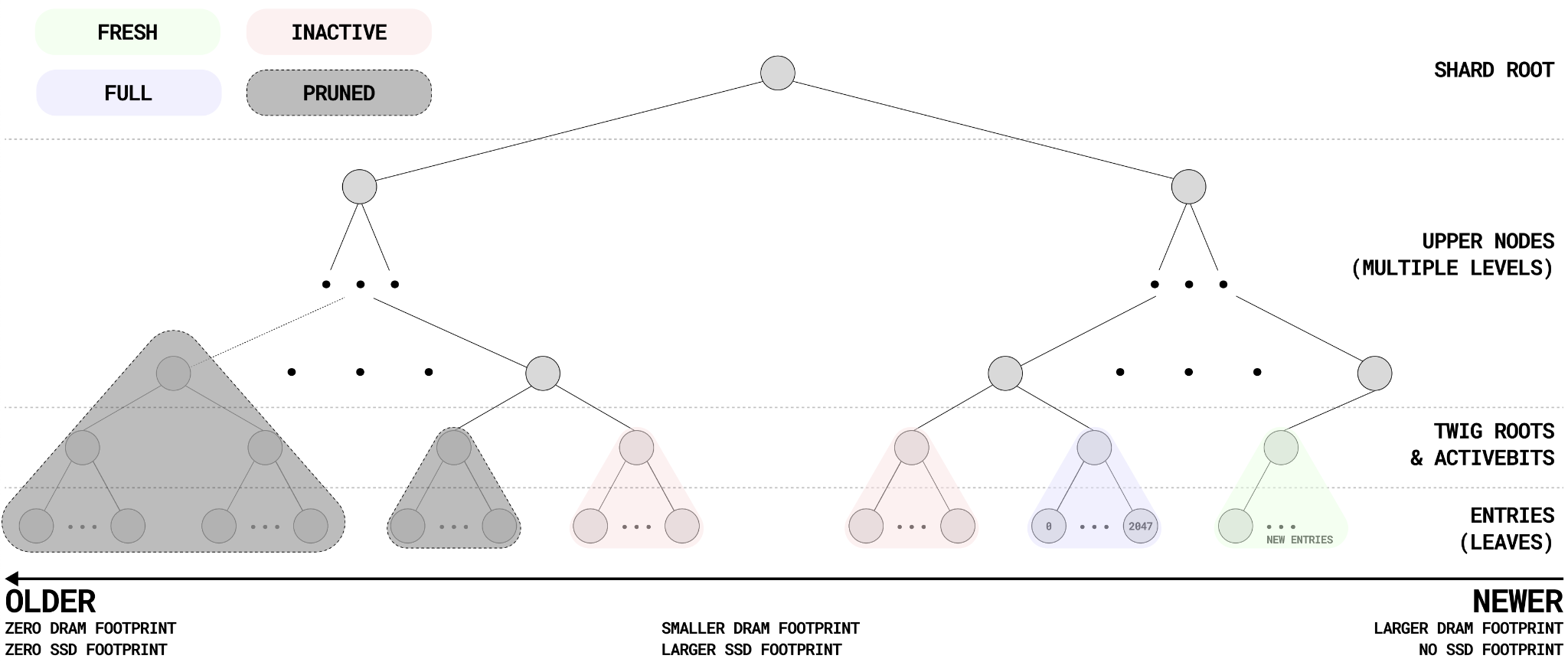
Twig-Based Append-Only Storage
QMDB divides its stored data into smaller, fixed-size pieces called "twigs." Each twig is like a miniature, unchangeable subtree. Because these twigs are added in an append-only fashion, QMDB doesn’t need to constantly rewrite data on the storage drive (such as an SSD). This design choice greatly cuts down on extra storage work and makes accessing the data more efficient.
In-Memory Merkleization
In many blockchain systems, proving the correctness of data (Merkle proof generation) can involve a lot of slow disk reads and writes. QMDB avoids this by doing all these proof-related calculations in a computer’s main memory (RAM). This means it can quickly produce cryptographic proofs, making the process much faster compared to traditional setups.
Optimized Indexing
Think of an index like a library’s catalog system that helps you quickly find a specific book. QMDB has a balanced indexing approach that uses both the computer’s memory (DRAM) and other data structures. This makes looking up and updating data swift, and it also simplifies retrieving older versions of the data (historical proofs).
Parallelized State Updates
QMDB is designed to handle multiple data updates at the same time (“in parallel”). It uses techniques called sharding and pipelining, which split and organize data tasks so they can happen together without getting in each other’s way. As a result, QMDB can handle millions of changes every second while keeping things running smoothly.
Scalability and Adaptability
QMDB can store a massive amount of information—over 280 billion entries—on a single server. It’s also flexible enough to work on both powerful enterprise machines and everyday consumer hardware. In other words, people from large businesses down to individual hobbyists can use QMDB without facing big hardware or cost barriers.
Historical Proofs and State Retrieval
One of QMDB’s standout features is how easily it lets you check older versions of the data. This is critical for use cases like auditing (making sure no one tampered with data), analyzing past transactions or states (forensics), and verifying states from a certain point in time (retroactive checks). This means users can trust that the data is accurate both now and in the past.
Performance Comparisons: QMDB vs. Other Solutions
QMDB represents a significant leap forward in verifiable key‑value stores when compared to traditional and incremental solutions like RocksDB and NOMT. In the case of RocksDB—which is a general-purpose key‑value database that does not incorporate Merkleization—QMDB achieves roughly 6× the throughput. This improvement is largely due to QMDB’s unified design that embeds Merkleization directly within the storage layer, thereby eliminating the extra disk I/O and memory overhead that arise from maintaining separate state storage and cryptographic proof generation layers.
When compared with a prerelease version of NOMT (the Nearly‑Optimal Merkle Trie Database), QMDB outperforms it by up to 8× in throughput. NOMT, despite its optimizations such as a flash‑optimized layout, still suffers from architectural separation. Its design requires duplicated data interactions between the physical key‑value layer and the Merkle proof generation layer, leading to extra disk reads and writes as well as higher memory footprint, which QMDB effectively avoids.
Beyond throughput improvements, QMDB has been validated under extraordinarily demanding conditions. Experiments have demonstrated its scalability with up to 15 billion entries—about 10× the expected state size for Ethereum in 2024. QMDB’s low memory overhead per entry implies that, on a single server, it can theoretically scale to support up to 280 billion entries. This scalability extends across both enterprise-grade and consumer-grade hardware, making it a transformative improvement for blockchain development by handling massive workloads with limited DRAM while simultaneously reducing barriers to entry and improving system decentralization.